

2·
1 month agoSORTED! Ended up patching it myself. Enjoy :D

Self Proclaimed Internet user and Administrator of Reddthat
SORTED! Ended up patching it myself. Enjoy :D
😥. I will fix it! I think because we are still going via nginx, it’s still has to pass the go-away challenges, which it must be failing and thats why…
Annnd, as we just moved I also only have key access to the server and I made all new keys and don’t have one on my other devices yet. (A classic)
Edit: nope, it’s now attempting to connect over https to the container… I think I’ll need to write a proper patch for it to allow for a override.
It also looks dead in the water/feature complete. So I’ve moved to FSFs container. (https://github.com/Fedihosting-Foundation-Forks/mlmym).
If I end up making a patch I’ll upstream. (I’m surprised LW hasn’t made one already)
Fun Pics:
I had to tell our main_nginx that it is “reddthat.com”.
services:
proxy:
image: docker.io/library/nginx
...etc...
networks:
default:
lemmy_internal:
aliases:
- reddthat.com
Now its: {user} -> CF -> {server_nginx} -> {frontend_nginx} -> mlmym => ((docker internal network)) -> {main_nginx} -> {{lemmy-ui/api}}
Instead of: {user} -> CF -> {server_nginx} -> {frontend_nginx} -> mlmym => CF -> {main_nginx} -> {{lemmy-ui/api}}
I believe I’ve fixed it.
A recent docker update no longer supports overriding hosts with hostnames. (I was telling mlmym that ‘reddthat.com’ is ‘lemmy-ui’. Which would make it request directly to the lemmy-ui container rather than going back out to CF and back again.
(For others/if you want to know the nitty gritty). I was doing this:
networks:
lemmy_internal:
extra_hosts:
- "reddthat.com:lemmy-ui"
Which did actually work, but now it doesn’t since I updated/installed docker compose v5.0.0.
(Seems the correctly enforce the host:IP format now). So I had to do a work around.
You rock too!
We’ve got oodles of gigabits!
:( yeah the outage notification woke me up.
As it was late I did a work around to temporarily fix it. I’ll be looking at it once I’ve had coffee.
Fixed up. All seems to be working. 😪
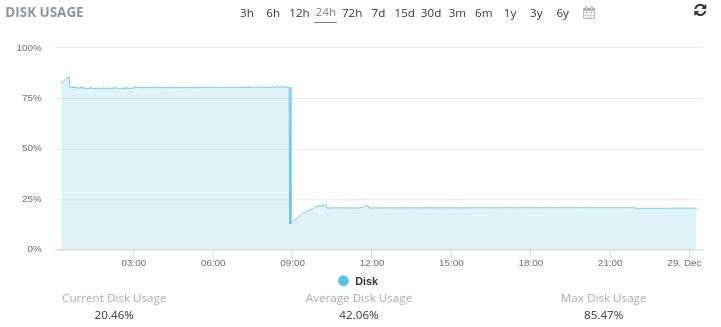
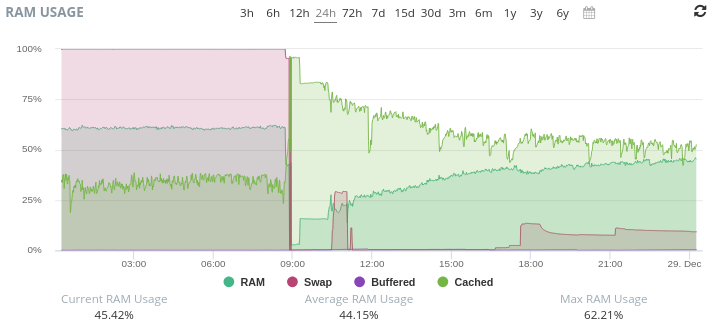
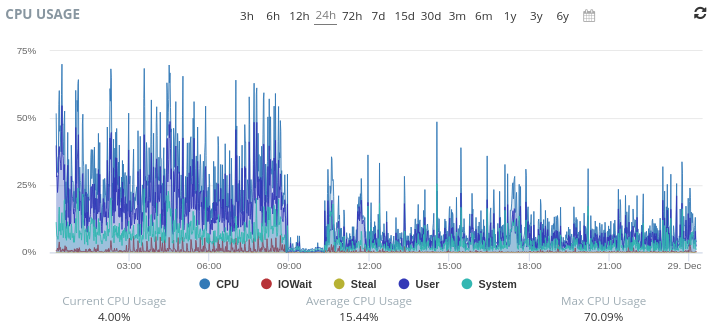
For those of you who were watching, check out our possible new status page: https://statusv2.reddthat.com/ (it has our CPU/Ram/Disk usages on display for everyone to peruse)
Working on fixing old.reddthat.com.
Migrated Successfully!
Pictrs Test: 
For our application process, as we only require 1 piece of information which is easily scriptable from the API (if someone were to go into that level of automating). But there is at this time 1+ people who regularly signup wait a week+ and then use the account to post something , wait 2 hours and then delete the whole account. (Resulting in all links and history to be deleted).
In the recent Lemmy update that fixed the exploit where even admins would no longer be able to view the account(s).
The actual bots on the other hand are completely dumb and could be automated away, but at the end of the day, I don’t want to destroy someone’s account creation due to some LLM hallucination.
And some are obvious bot names, (like “holidaydestination”) but still fill out the form correctly.
Reports are case by case basis with a fair amount of leeway for reddthat users as just because I am from a specific country doesn’t mean I have the right to impose my biases on others.
🦘🦘🦘
that’s what I get for not whitelisting the health checker*
We are up now :s !
I’ll that sorted
We are back!

It’s been sorted on our side! Thanks for the pings
Yeah we have implemented go-away on https://old.reddthat.com/ but only as a test and it’s worked well. I haven’t made the time to implement it for our main endpoint.
I also want to do exactly that, only show the challenge for non-logged in users which adds a small bit of complexity but my $job has been flat out recently. So I’ve only been doing moderation duties rather than server admin duties.
But I can think of plenty of edge cases that something could happen or affect regular users and I don’t want that to happen. Normally the bots are all like the ones we just had, using open proxies/residential proxies and querying either posts or the API directly.
I’m hoping to carve out some time in the next month to coincide with this maintenance or our server migration to do some solid testing.
Unfortunately not. We are in a queue that will happen… Whenever OVH (our server host) lets me know.
The outage/downtimes just now were because an AI scraper just brought down the server. We had ~81000 unique IPs spam our little server. It wasn’t a smart AI scraper so I managed to block them and we are back to being up and working.



{kind=link}
Thanks, patched and its page=2 now. (I wonder how LW never managed to see that… They must not be using that image…!